
实验内容与步骤
1. 配置网络环境:
本次实验用的是Cent OS 6.5 minimal版本,相应的版本可以在官网上下载。
首先安装:
我是用的是parallels desktop 来安装,安装步骤详见:
链接: Mac os上配置PD虚拟机,使其共享网络访问公网.
vi /etc/sysconfig/network-scripts/ifcfg-eth0进行网络环境的相关配置: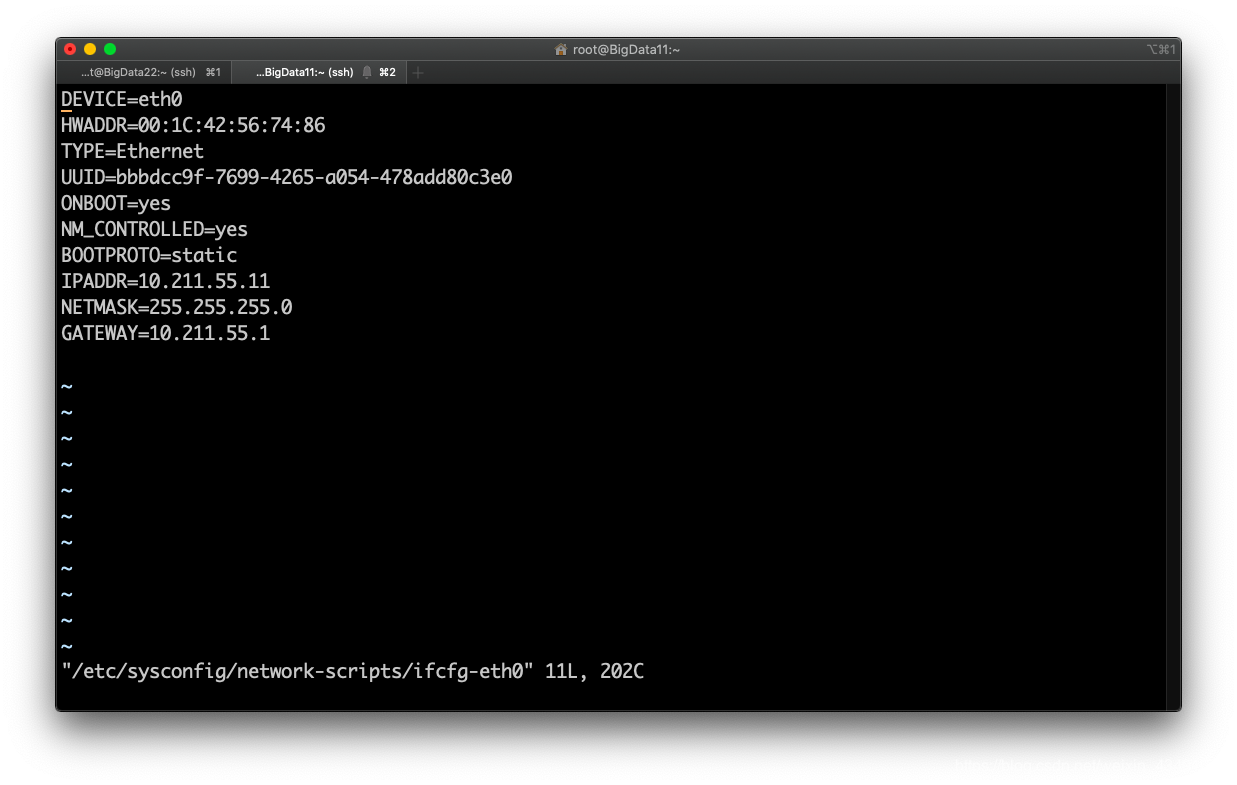
设置DNS解析(不同的系统不一样):vi /etc/resolv.conf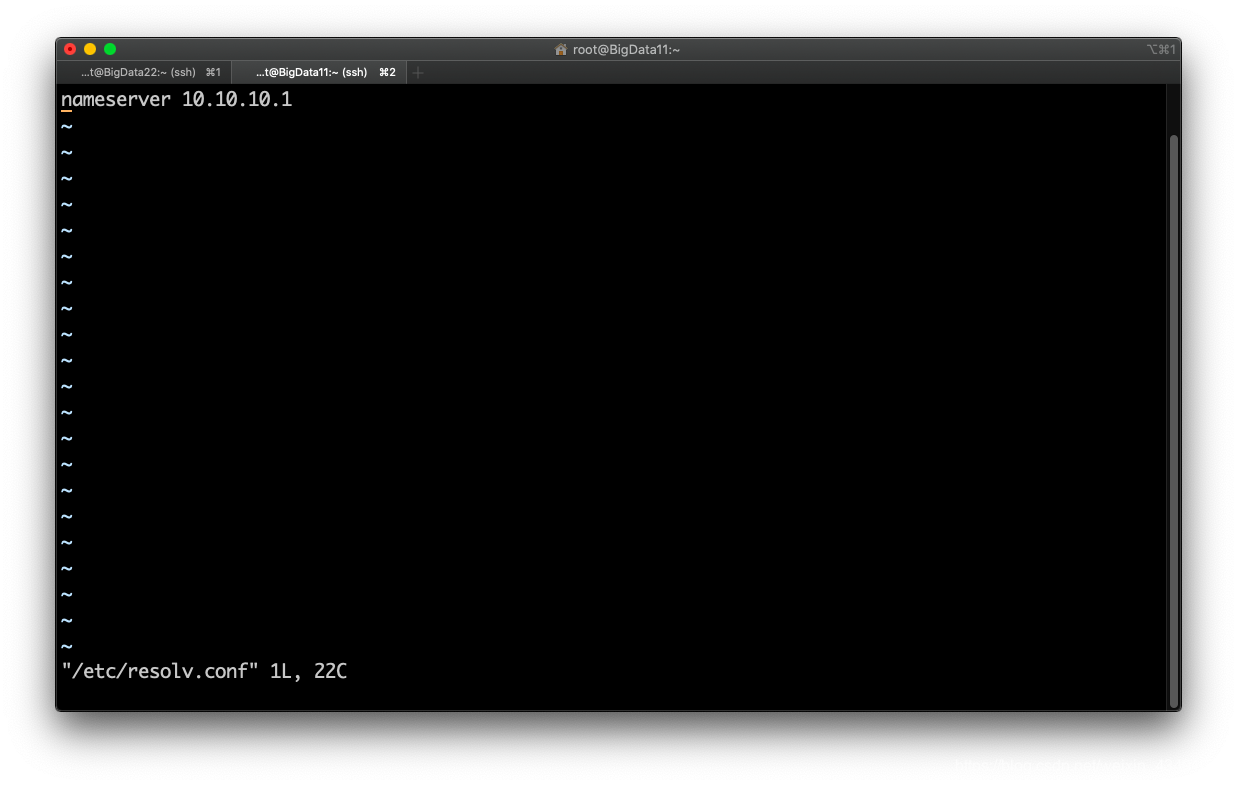
service network restart命令,重启网络服务。
测试网络: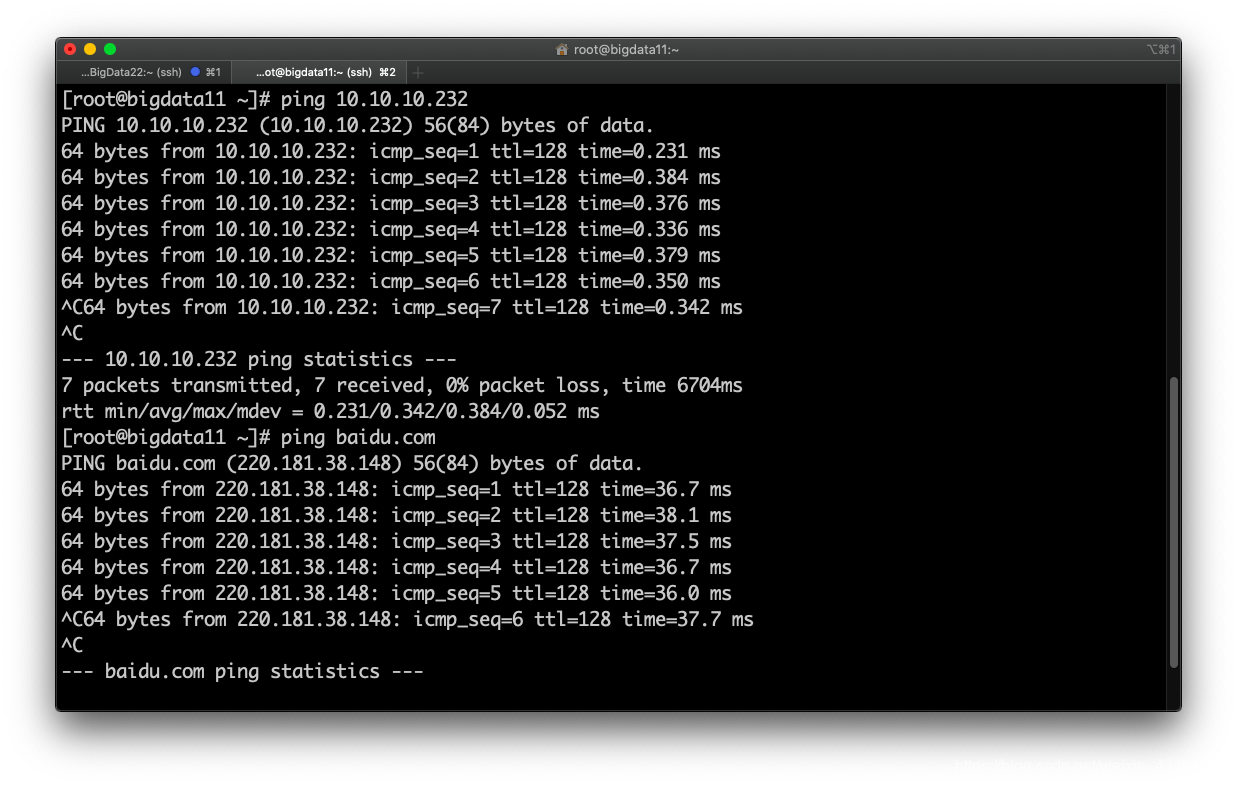
ping自己和外网都能通,网络配置成功。
2. 时间同步ntp:
1 | yum -y install ntp ntpdate |
以上命令进行时间的同步: date查看当前时间
3. 克隆系统:
前两步做好了之后,可以关机,然后将系统进行克隆,因为需要配置Hadoop的完全分布式搭建,所以克隆了两个主机。
主机克隆后,需要将网络环境重新配置一下,将硬件地址和UUID删除,并将IP地址更换,之后删除Linux物理地址绑定的文件(该文件会在操作系统重启并生成物理地址以后将物理地址绑定到IP上)rm -rf /etc/udev/rules.d/70-persistent-net.rules
当然,也可以更改一下主机名称:vi /etc/sysconfig/network
将HOSTNAME=后面的内容更改成需要的名称即可。
修改网络映射hosts
vim /etc/hosts
1 | 例子: |
最后需要重启一下系统:shutdown -r now 或者init 6
最后的效果:
4. 免秘钥操作:
生成密钥
ssh-keygen -t rsa # 一路回车将集群中的所有公钥集中到某台机器,生成免密授权登录文件
bigdata22:1
scp ~/.ssh/id_rsa.pub bigdata11:/root/.ssh/22
bigdata33:
1
scp ~/.ssh/id_rsa.pub bigdata11:/root/.ssh/33
bigdata11:
切换到根目录下的.ssh文件中:1
2
3cat id_rsa.pub >> authorized_keys
cat 22 >> authorized_keys
cat 33 >> authorized_keys对文件进行授权:
chmod 600 authorized_keys
必须改,不然不能免密登录将授权列表分发给bigdata22和bigdata33:
1
2scp ~/.ssh/authorized_keys bigdata22:/root/.ssh/authorized_keys
scp ~/.ssh/authorized_keys bigdata33:/root/.ssh/authorized_keys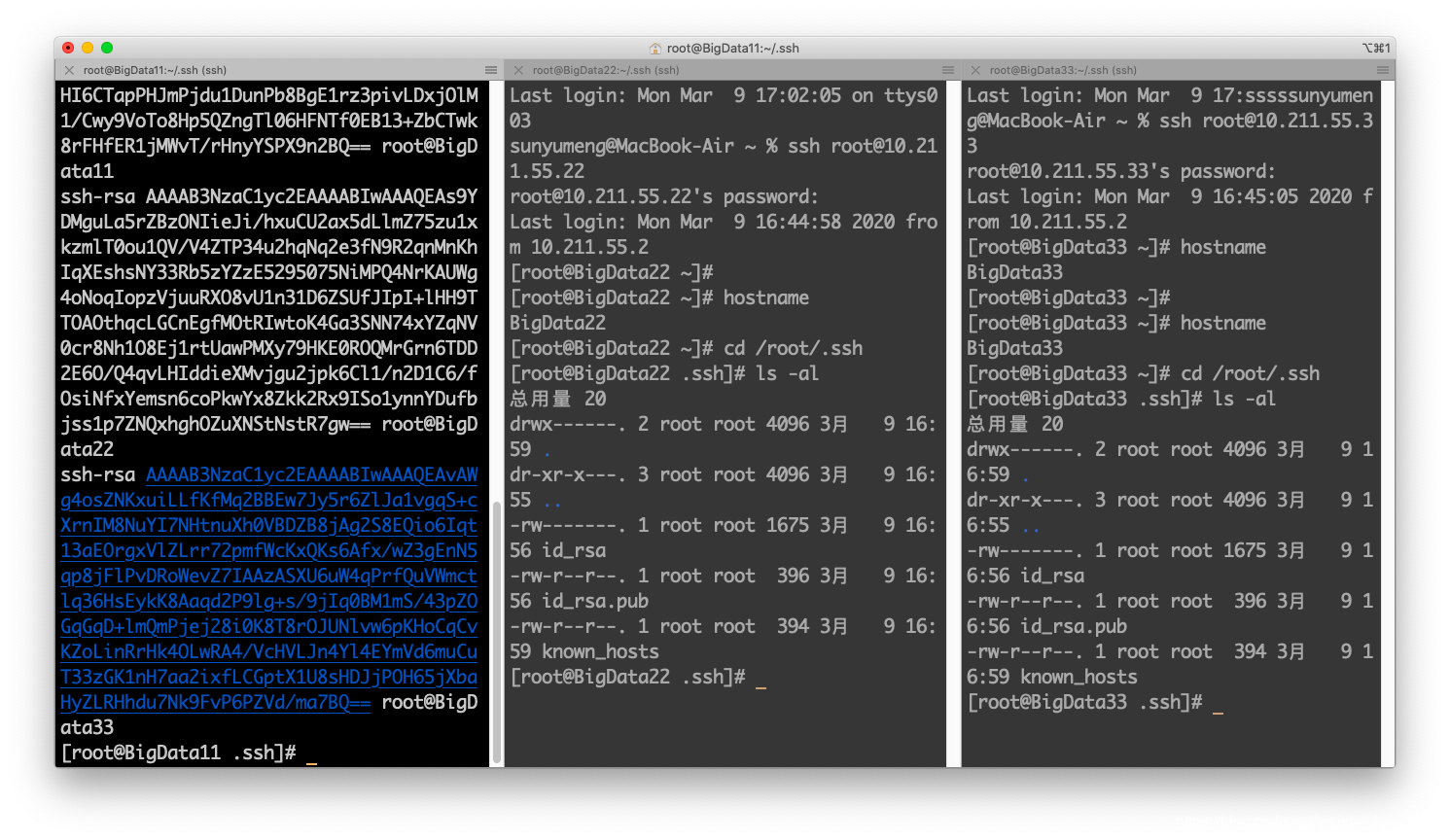
5. Jdk和Hadoop安装配置:
利用ForkLift将所需要的jdk文件以及Hadoop文件拷到三个主机上:
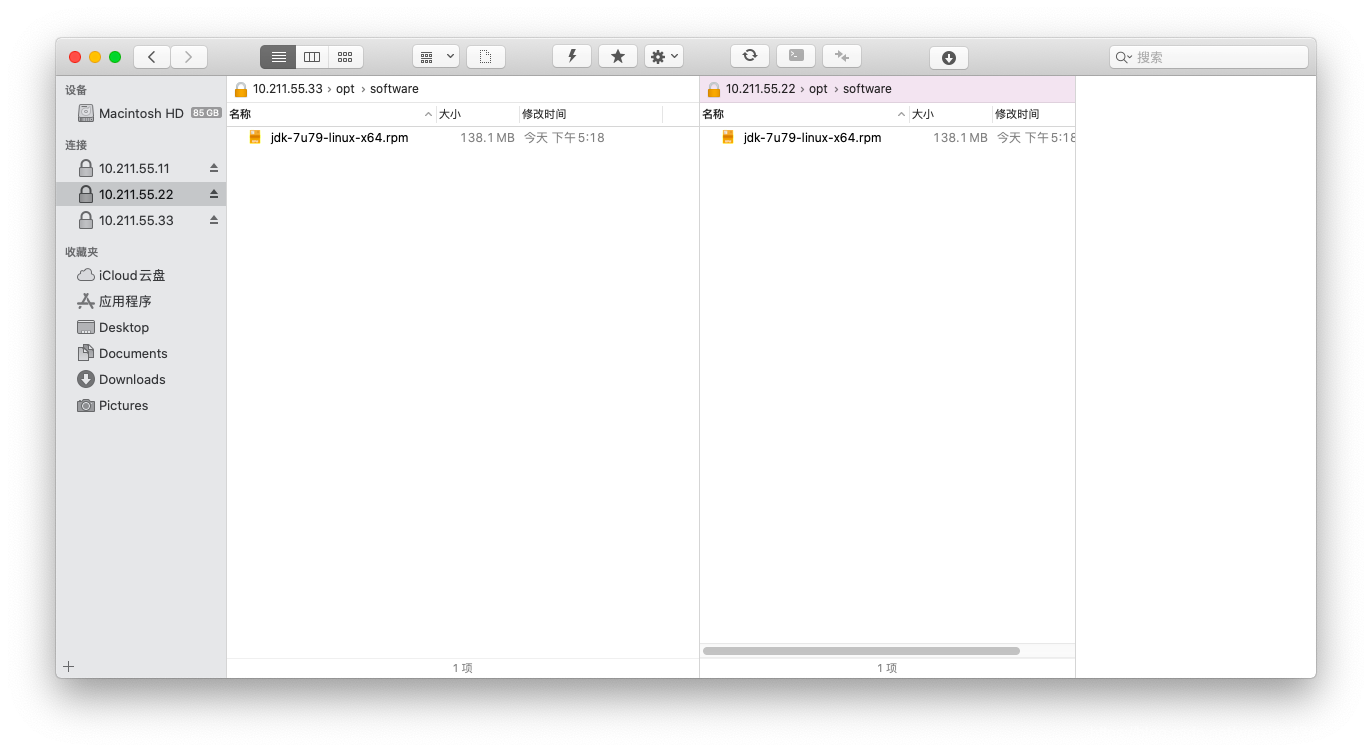
可以先配好一台机器中的配置文件,再将软件复制到其他机器,减少配置的工作量。
rpm -ivh 命令安装rpm包,安装默认路径: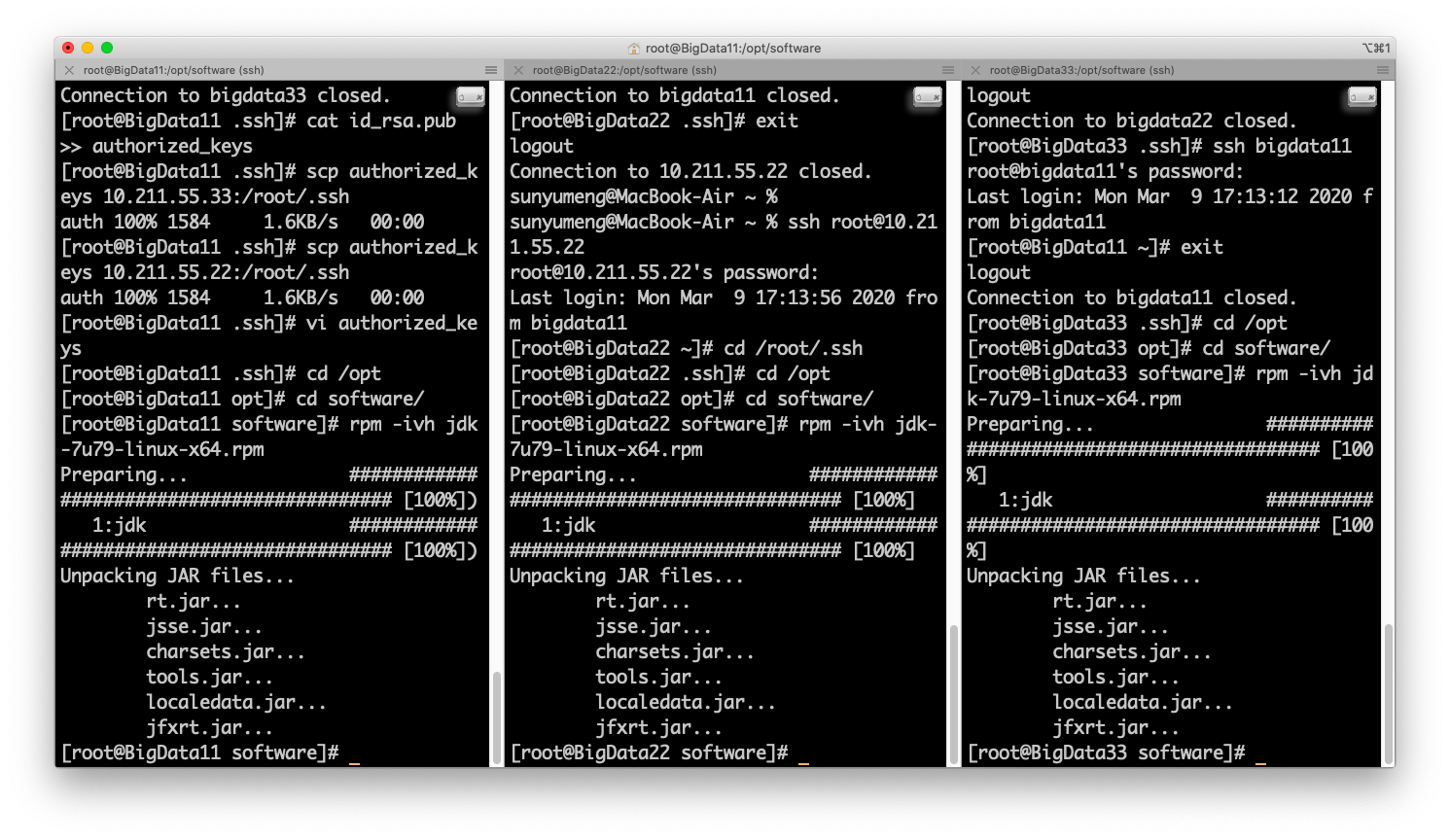
配置环境变量:vi .bash_profile
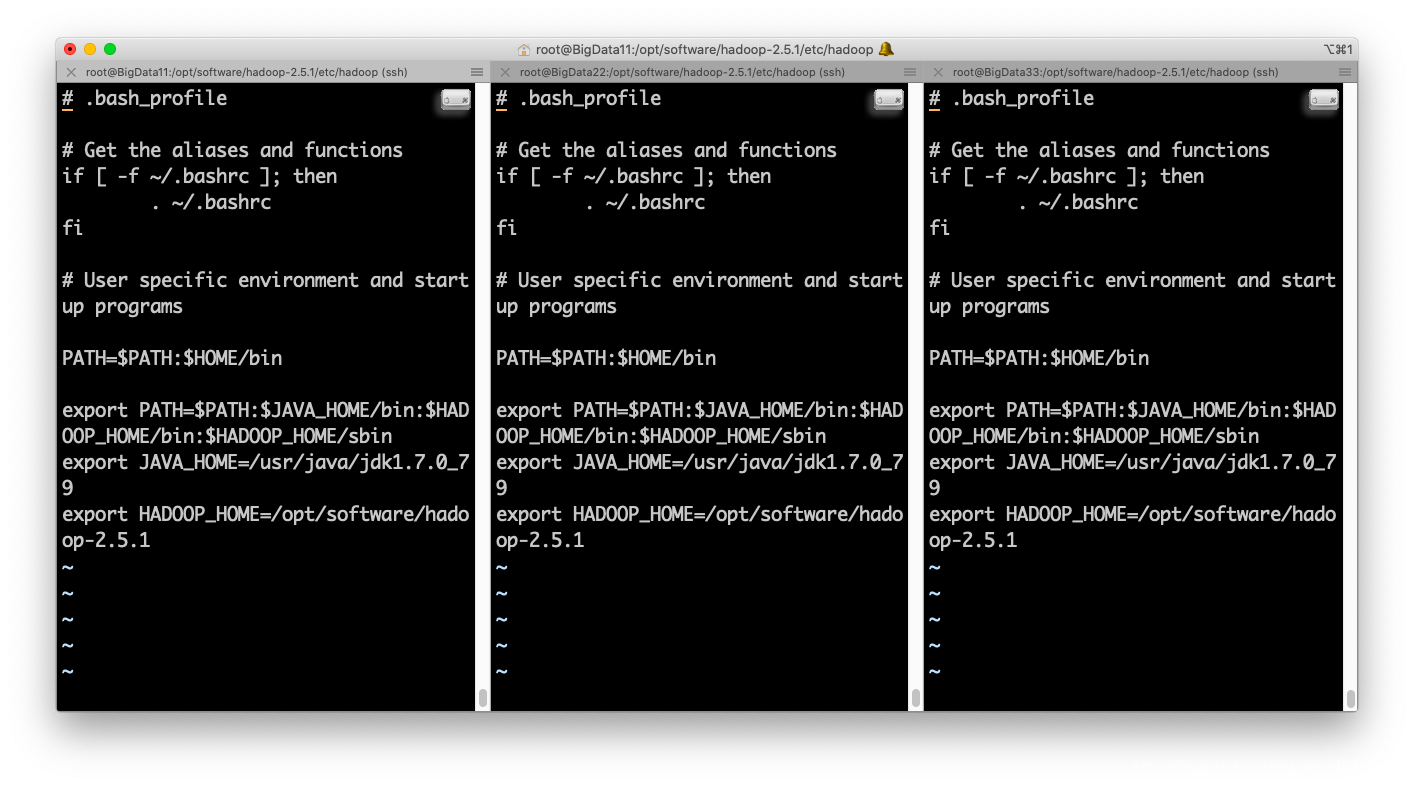
需要source .bash_profile加载一下。
测试环境JDK:
HADOOP 安装配置:
- 安装源码包用tar -zxvf
Cd /opt/software tar -zxvf hadoop-2.5.1_x64.tar.gz - 配置环境变量
1
2
3
4
5Vi /root/.bash_profile
export PATH
export JAVA_HOME=/usr/java/jdk1.7.0_79
export HADOOP_HOME=/opt/software/hadoop-2.5.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 加载环境变量
1
Source /root/.bash_profile
6. core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml配置:
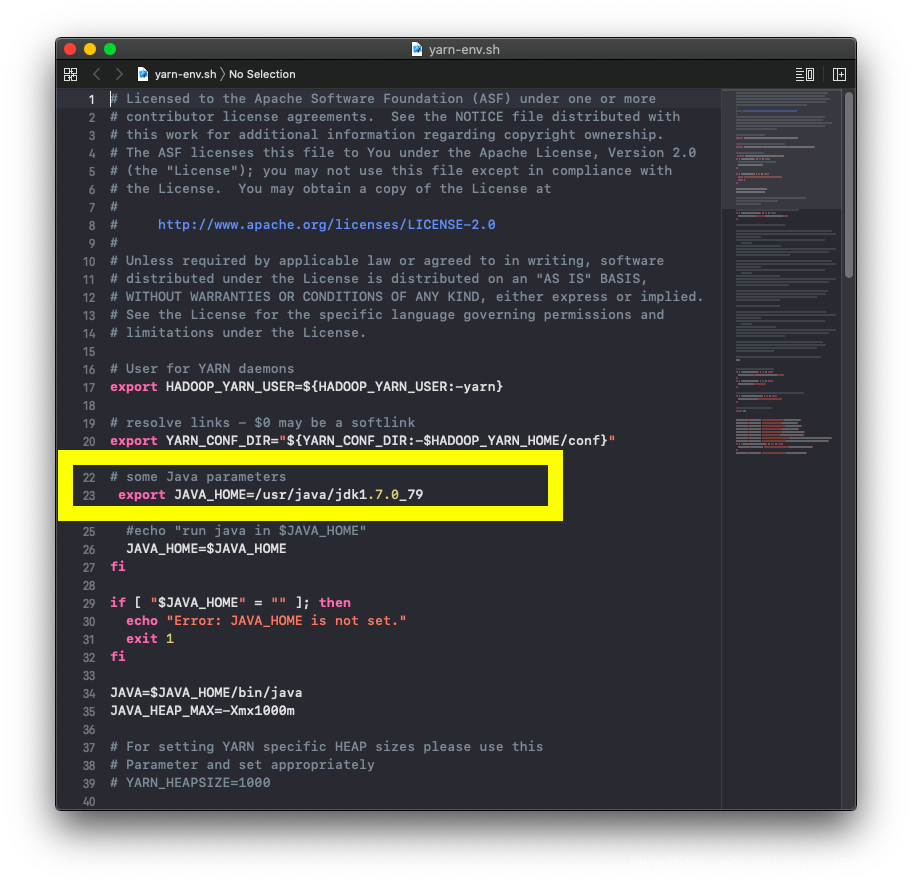
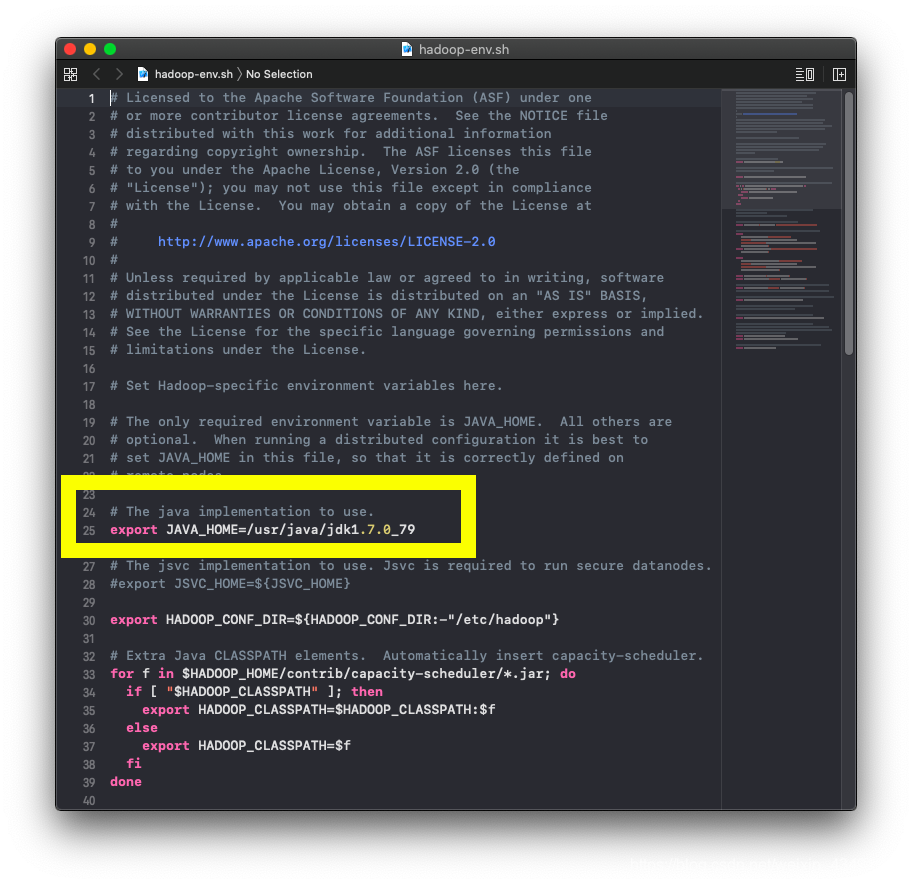
hadoop-env.sh 和 yarn-env.sh 中将Java的环境变量添加:
core-site.xml配置:

代码片段:
1 | <property> |
- hdfs-site.xml配置:
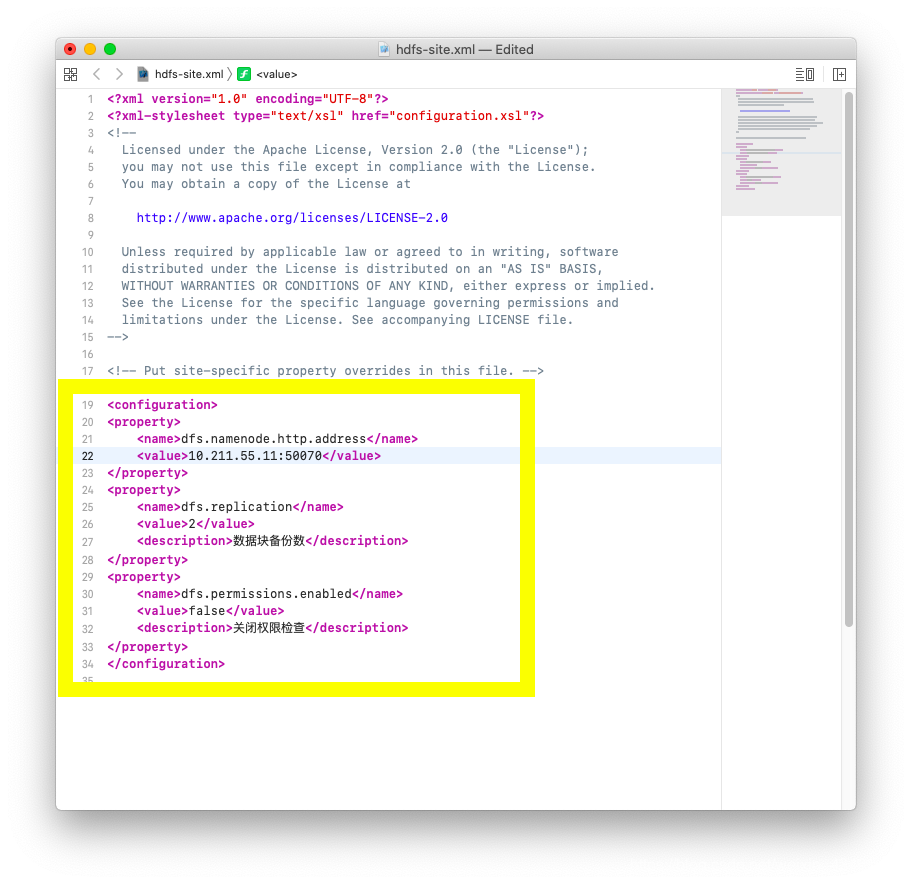
代码片段:
1 | <property> |
- mapred-site.xml配置:
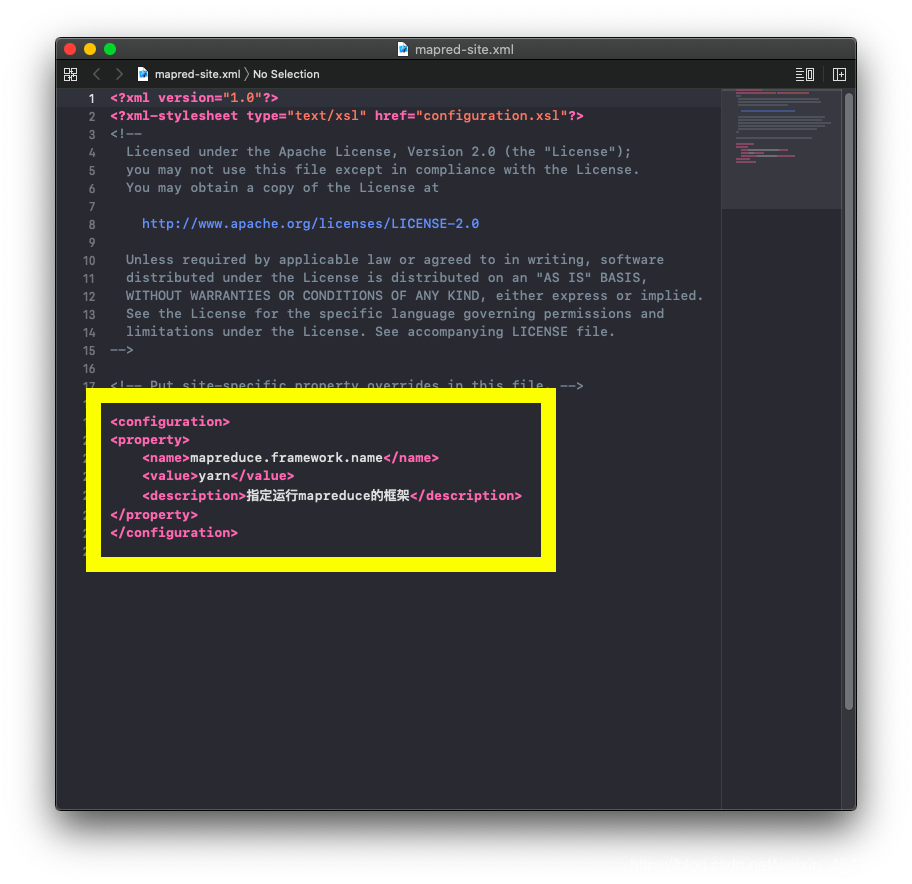
代码片段:
1 | <property> |
yarn-site.xml配置:
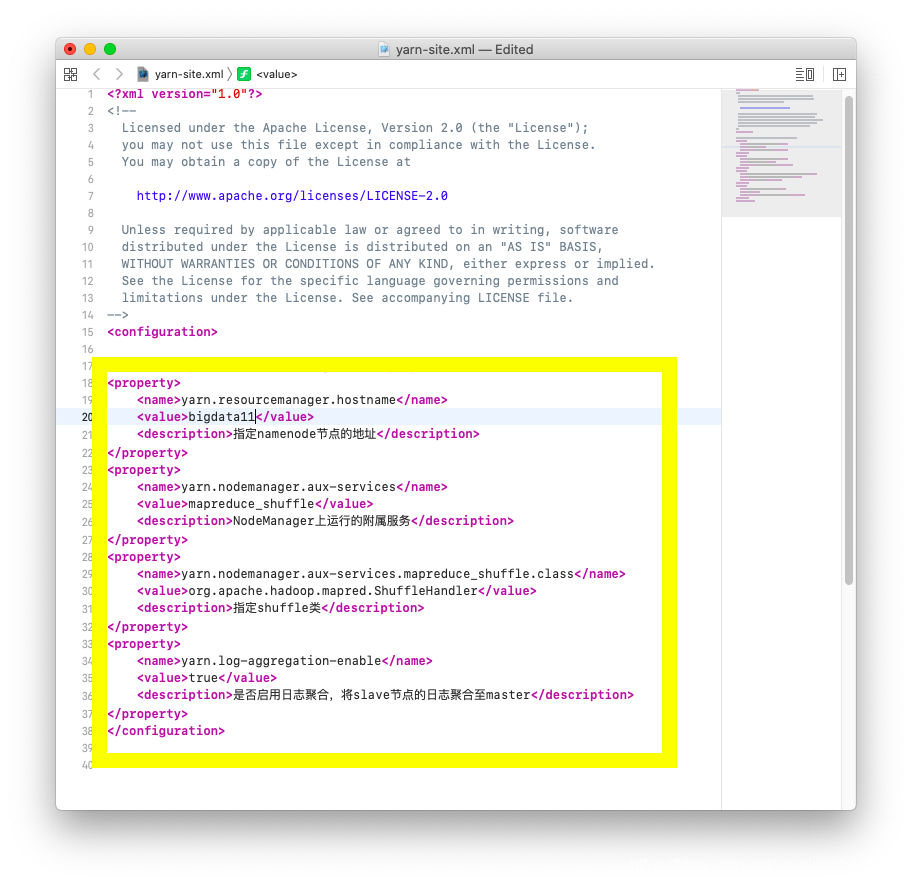
代码片段:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定namenode节点的地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
<description>指定shuffle类</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>是否启用日志聚合,将slave节点的日志聚合至master</description>
</property>将配置好的文件包分别发至其余两个主机上:
scp -r /opt/software/hadoop-2.5.1 bigdata22:/opt/softwarescp -r /opt/software/hadoop-2.5.1 bigdata33:/opt/software
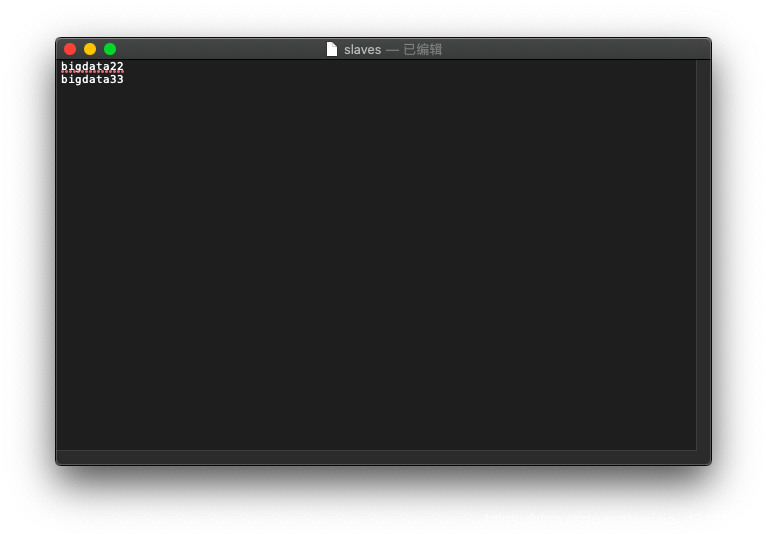
更改bigdata11上的slaves文件:
7. 格式化启动节点:
启动hadoophadoop namenode -format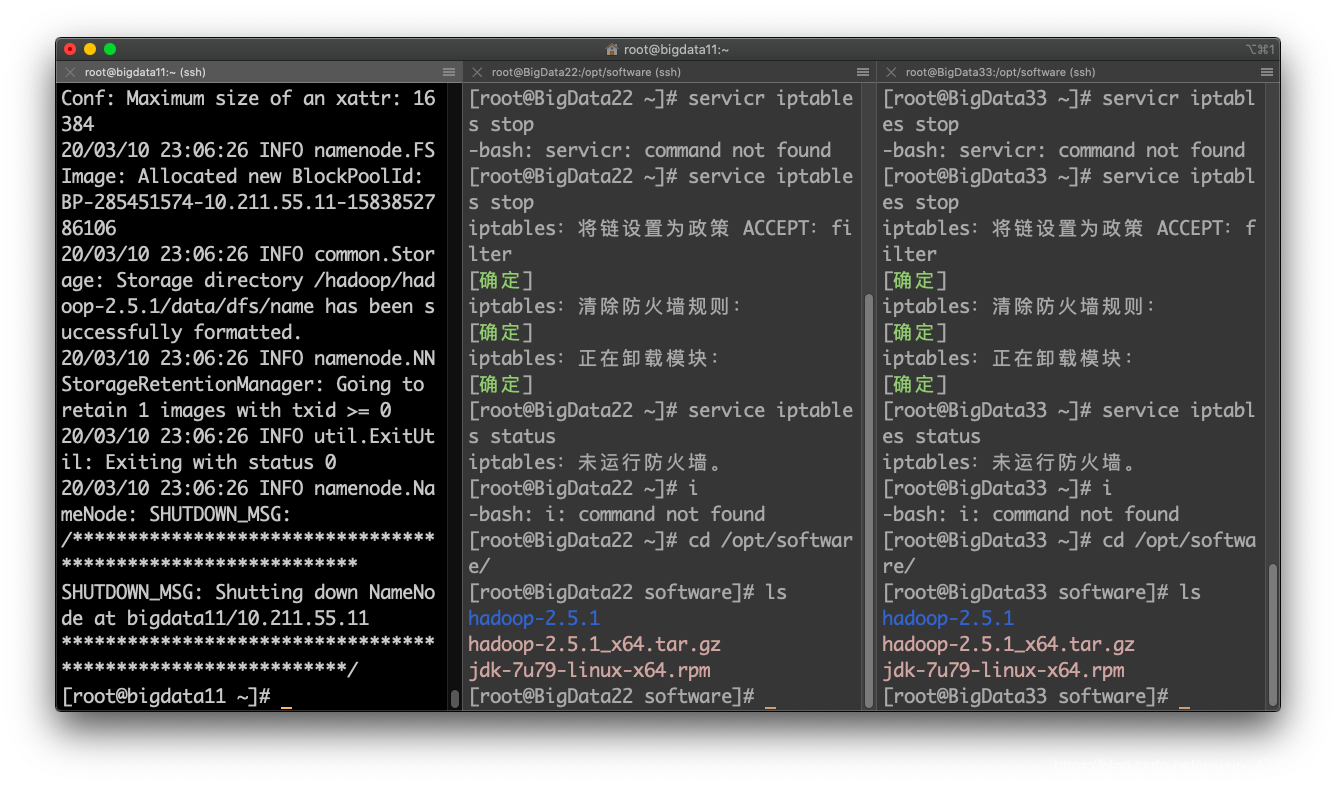
启动hdfsstart-dfs.sh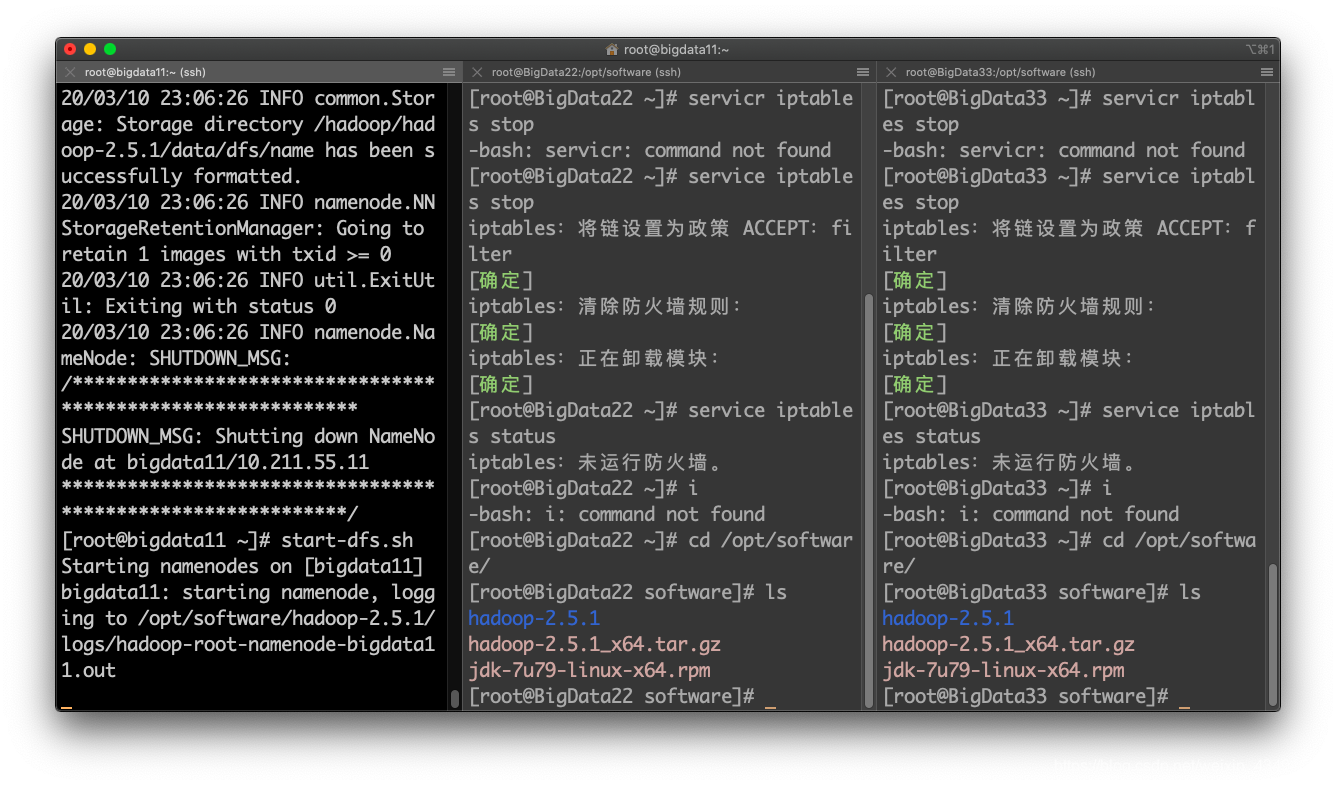
启动yarnstart-yarn.sh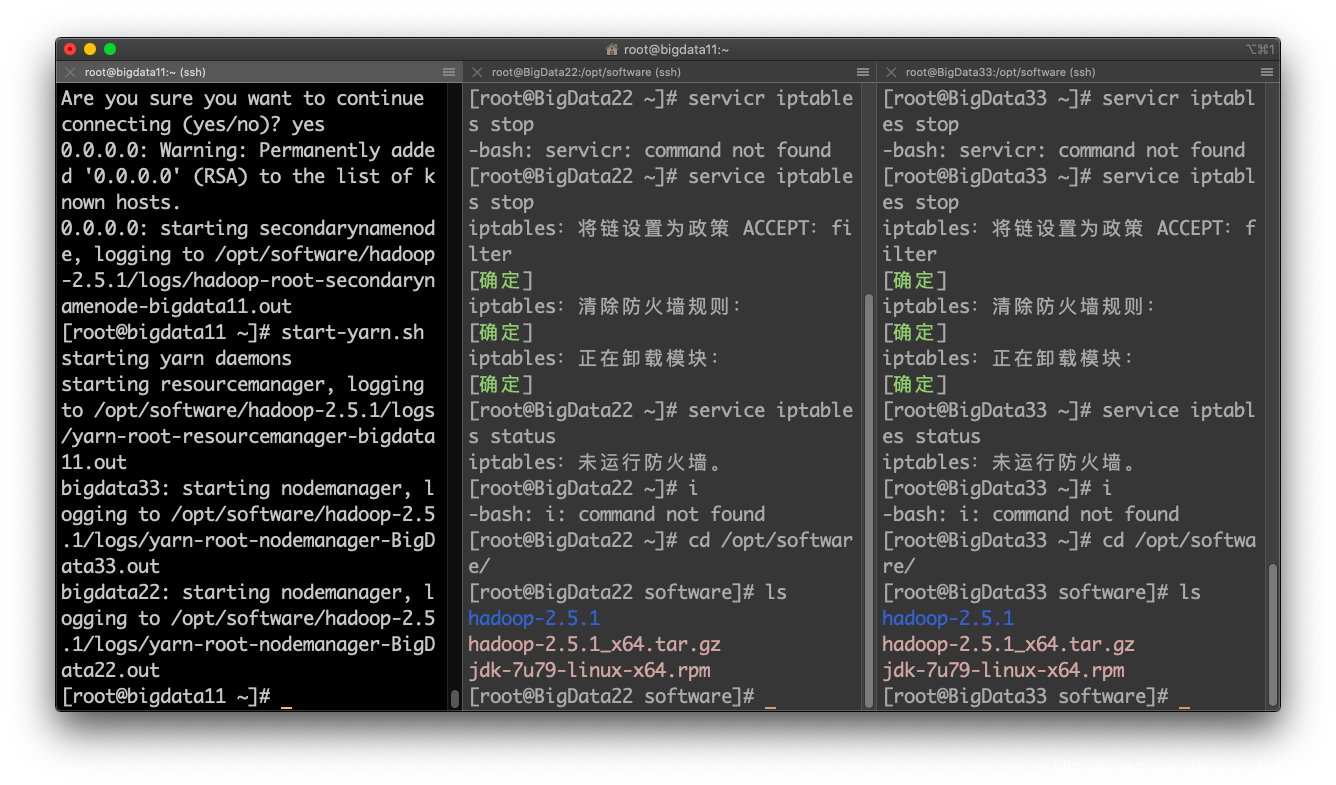
查看一下状态:
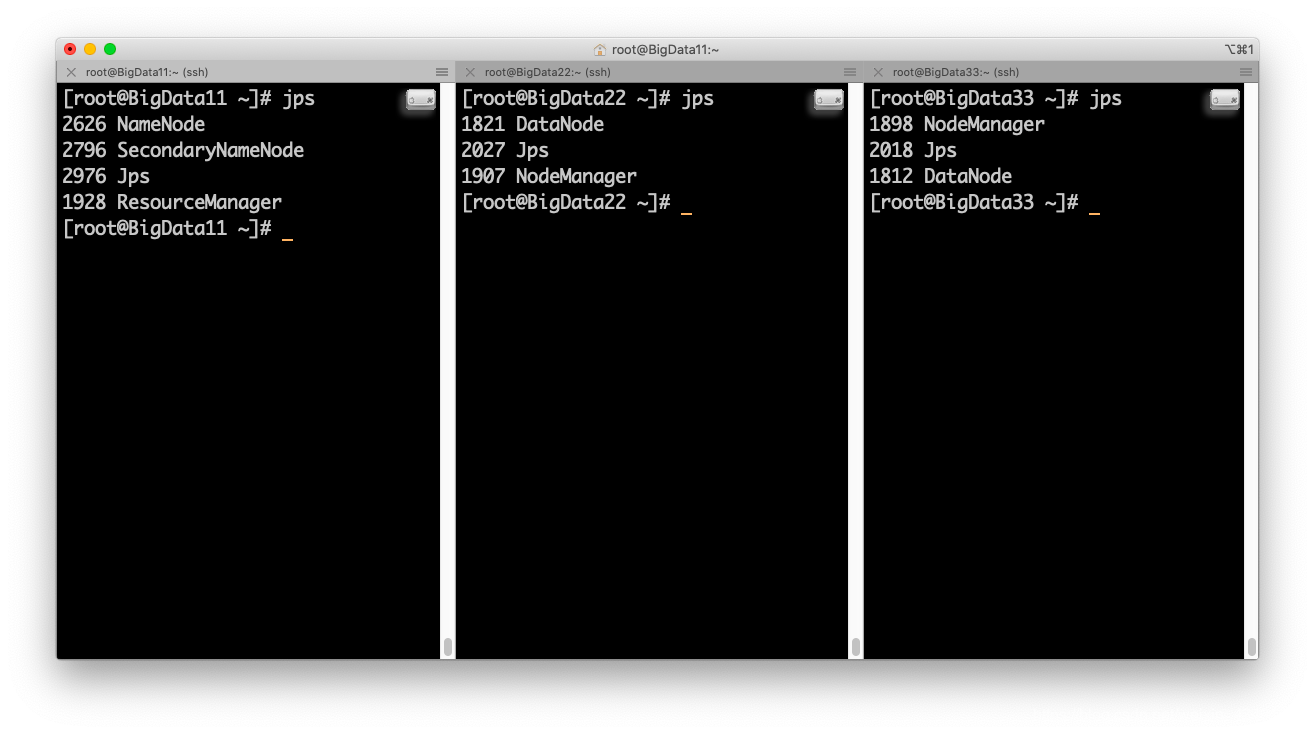
8. web访问测试:
- HDFS的web端: http://master:50070
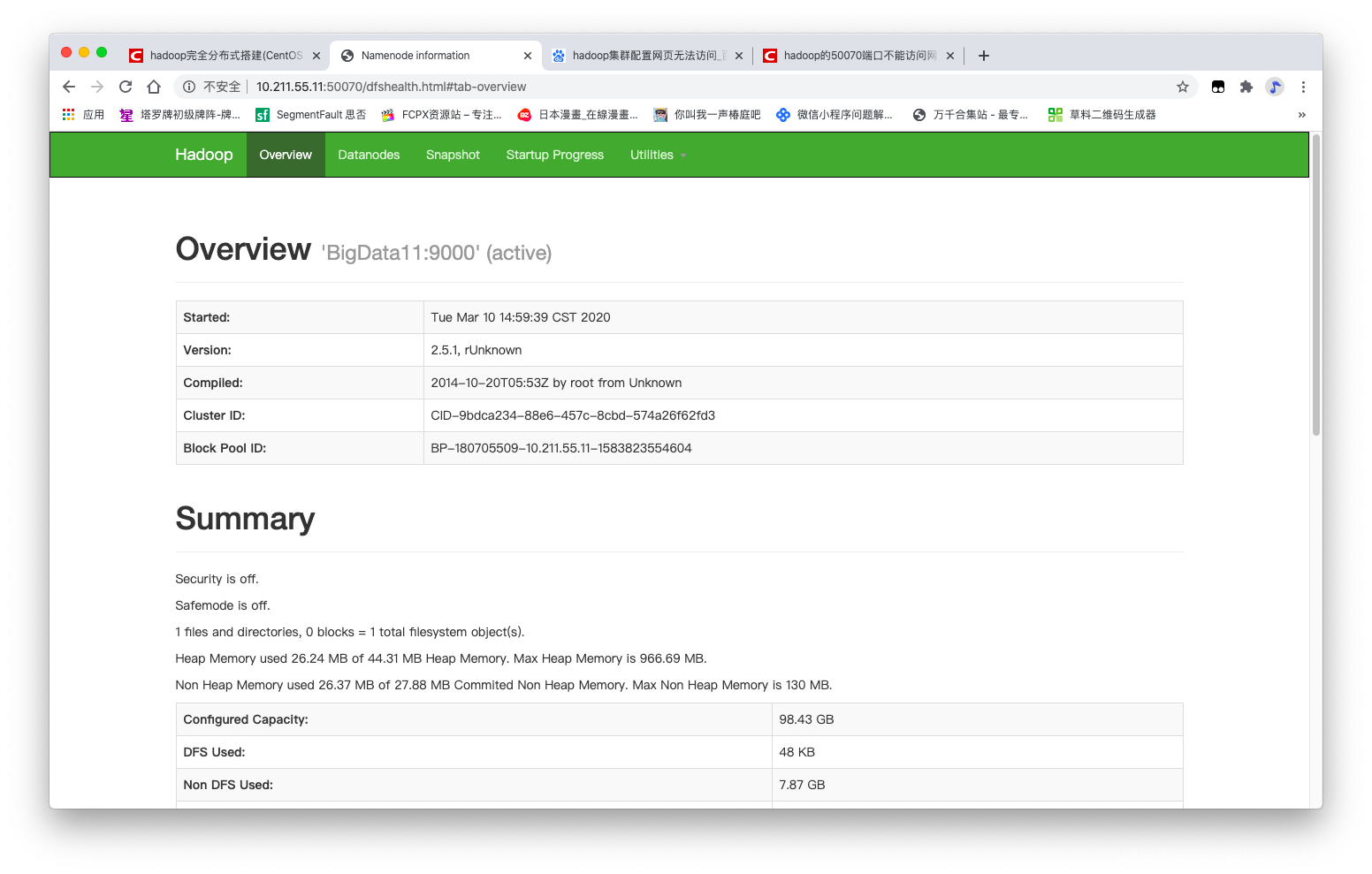
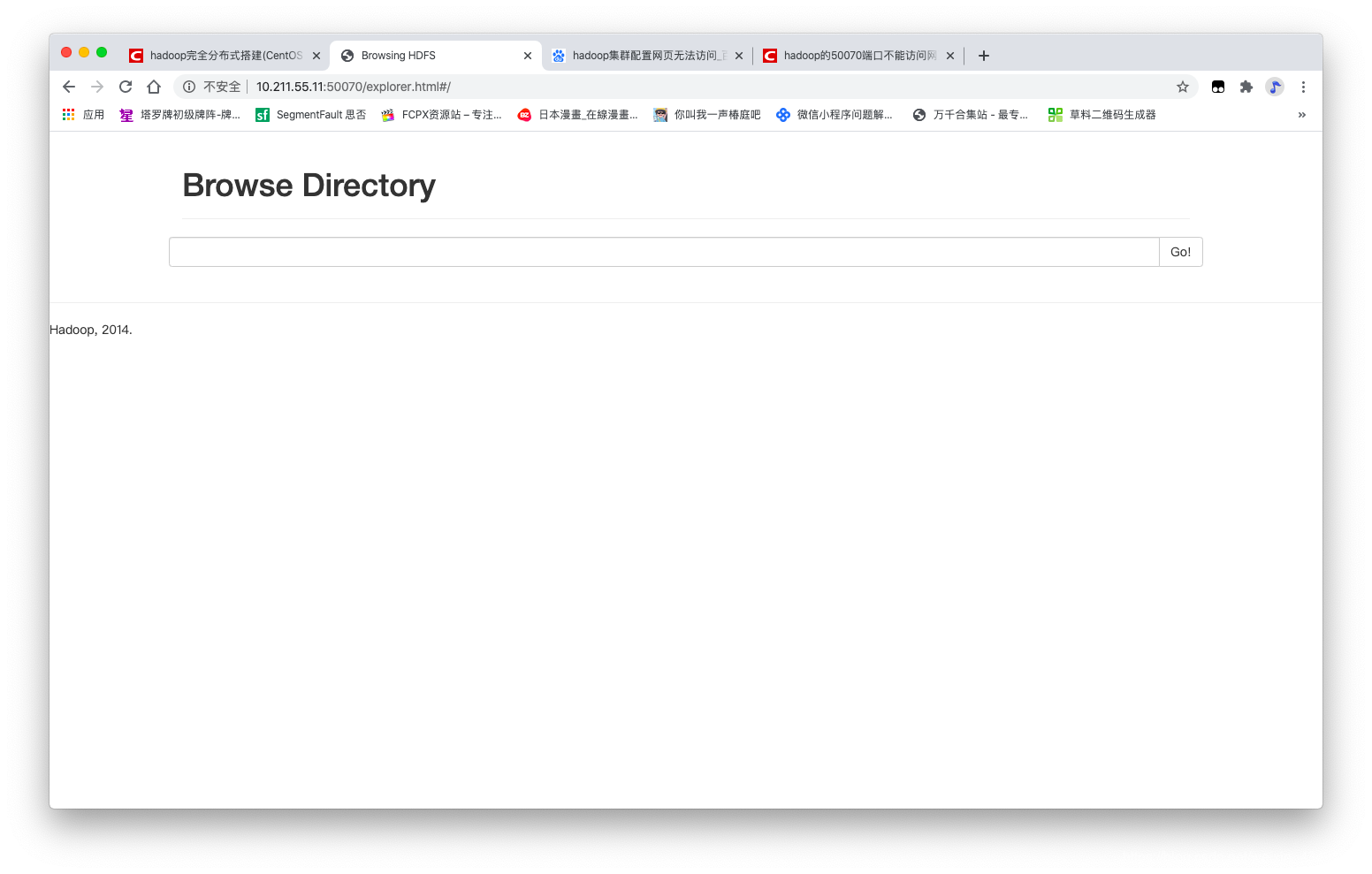
- MapReduce的web端: http://master:8088
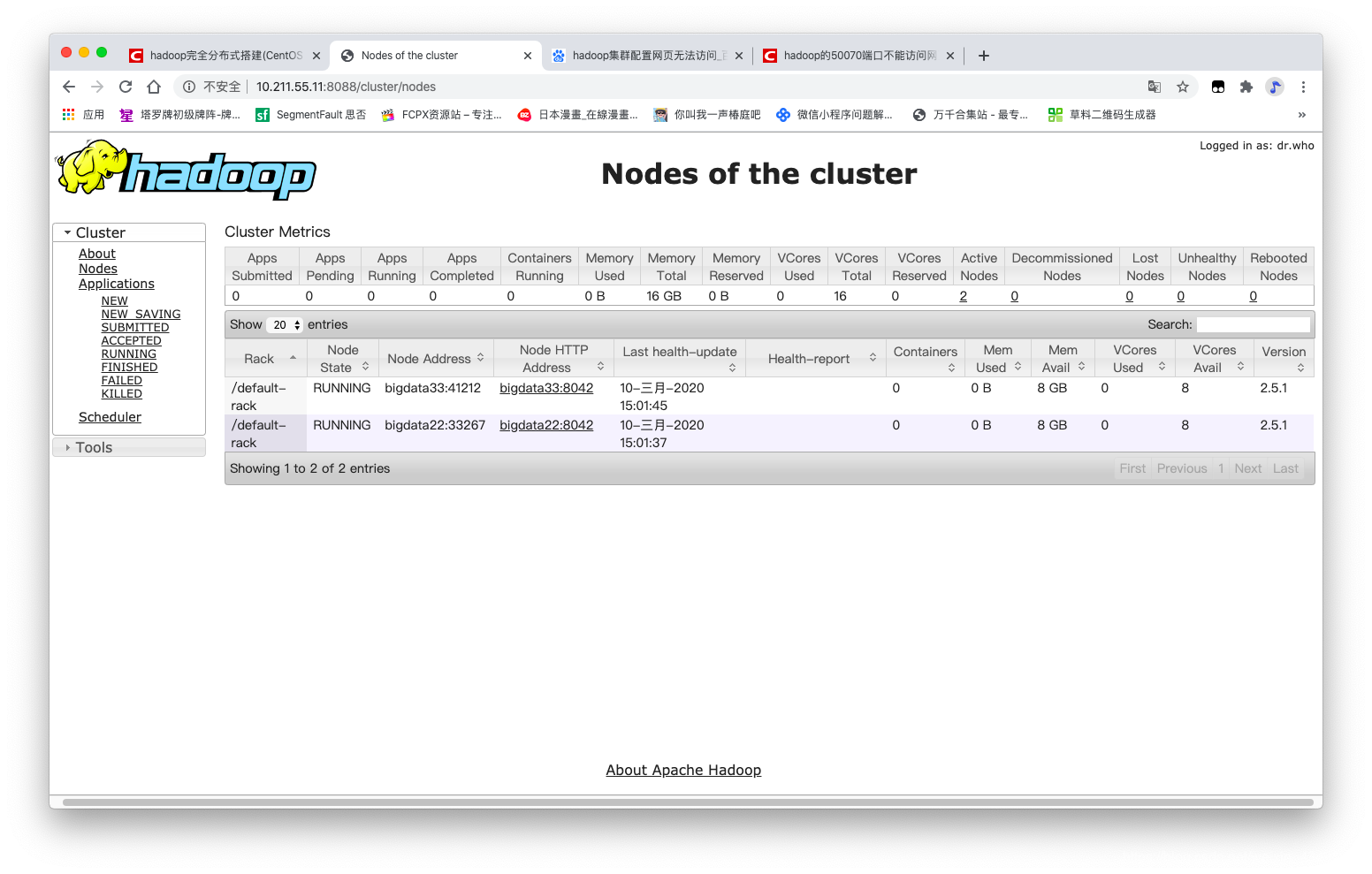
成功访问,环境搭建完成。